C# コンソールアプリケーション 自然言語解析 音声合成 音声認識
音声から感情を分析してみた
2019/03/27
はじめに
前回の記事に続き、NTTコミュニケーションズのCommunication Engine"COTOHA API"の試用レポートです。
岩手岩泉町在住のプログラマAです。何も考えずにキーボードをたたいてたら"CONOHA API"で検索してました。1文字違いで紛らわしいです。
COTOHA APIを使い始める方法については前回記事を参照いただくとして、今回はCOTOHA APIのうち"感情分析"APIを使ってみました。
APIリファレンスによれば、リアルタイム対話での分析というより、あらかじめ書かれた文章を分析することが想定されているように見えます。
「書き言葉」か「話し言葉」かでいえば、「書き言葉」が対象にも見えますが、COTOHA API/文タイプ判定APIのように「'default' - 通常文」「'kuzure' - SNSなどの崩れた文」のようなtypeパラメータの指定が無いので、どちらのパターンも学習しているのかなと勝手に想像(期待)してしまいます。
検証プログラムはGoogle Cloud PlatformのCloud Speech-to-Text(以下GCP STT)で音声をテキストに変換し、COTOHA APIで感情分析した結果を画面に表示する構成とします。
プラスアルファでCOTOHA APIで言い淀みを除去した結果テキストをWindowsのText to Speech/TTS API(SpeechSynthesizer)でテキストから音声に変換し、スピーカから出力します。
(前回のリベンジです。PCのSpeechRecognitionEngine(STT)ではうまく?言い淀みが入力できませんでしたが、GCP STTではどうでしょうか。)
プログラム
C#、Windowsデスクトップ/コンソールアプリケーション
サービス/API
- COTOHA API/感情分析API V1、言い淀み除去 β版
- Google Cloud Platform/Cloud Speech-to-Text(ストリーミング入力※参考1)
- Synthesis API(TTS)/Windowsローカル
実行/開発環境
- Windows 10 Pro バージョン 1809(デスクトップPC )
- Visual Studio 2017 Community
- ヘッドセット
- スピーカ(ヘッドセット)
NuGetパッケージ
- Google.Cloud.Speech.V1 Pre
- NAudio 1.8.5
- Newtonsoft.Json 12.0.1
準備
1.マイク、スピーカ準備
PCの録音デバイスとしてヘッドセットを、再生デバイスとしてスピーカ/ヘッドセットを接続し、よしなに動作を確認しておきます。
Windowsの設定 > プライバシー > 音声認識の設定は利用しません。ざっくりいうと、音声は録音デバイス(マイク)->NAudio->GCP STT Client(Google.Cloud.Speech.V1)->GCPの経路で流れます。
(NAudioはメジャーな音声ライブラリなので、設定でハマるような事はないと思われますが、動作しないようならGoogle先生に聞いてください。)
2.COTOHA APIアカウント作成
前回記事参照で。
3.Google Cloud Platformアカウント作成
12か月間の無料トライアルを申し込みましょう。無料といっても、しっかりクレジットカード番号の登録を求められますが、いつの間にか課金が始まる事はないと強調していますので信用しましょう...。
アカウント作成・ログイン後のスタートガイドから「APIとサービス」 > 「+APIとサービスを有効化」 > 「Cloud Speech-to-Text API」をたどります。
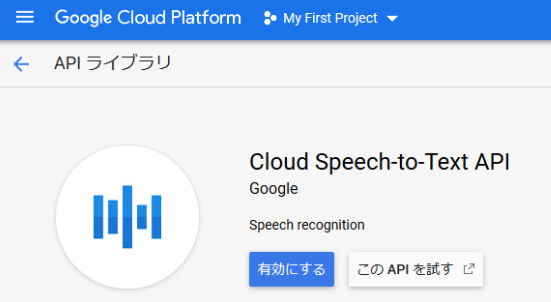
上の画面で[有効にする]をクリックすると、
APIでは有効な課金方法が必要です。
[キャンセル] [課金を有効にする]
のダイアログが出ます。大丈夫か?公開済みの有料課金APIだから?と、ドキドキしながら[課金を有効にする]をクリックします。(数日使ってもGCPの「お支払い-レポート」に請求金額がでてないので大丈夫そうです。)
「APIを有効にしています」メッセージが消え画面が切り替わると、今度は
というメッセージが画面上部に出るので[認証情報を作成]をクリックして先に進みます。(私の場合、次に表示される認証情報の種類を調べる画面はスキップしました。画面が遷移しなかったので...。)
あらためて「APIとサービス」画面の左メニューで「認証情報」を選択します。[認証情報を作成]をクリックすると以下のリストが表示されるので「サービスアカウントキー」をクリックします。
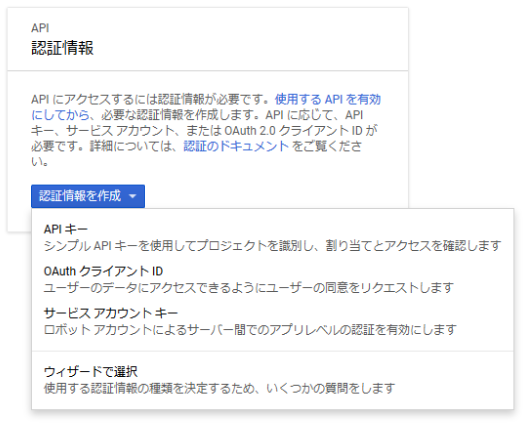
サービスアカウントの詳細を設定・作成します。
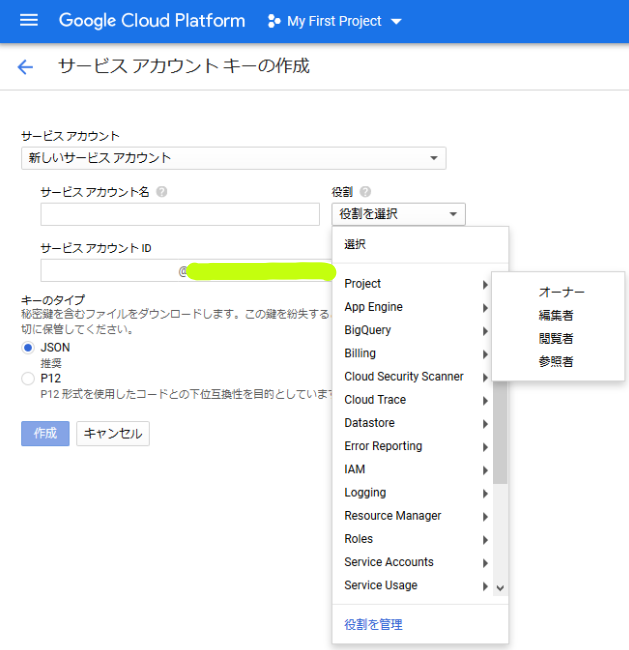
【設定項目】
- サービスアカウント名
- └─******(任意)
- 役割
- └─Project > オーナー
- キーのタイプ
- └─JSON
最終的に認証情報をファイルとしてPCにダウンロードします。(今回はJSONファイル)
GCPクライアント(Google.Cloud.Speech.V1)はAPIへのアクセス時、このファイルの情報により認証する必要があり、そのパスを環境変数で指定する仕様(※参考2)になっています。今回は検証という事でユーザ環境変数に以下を設定しました。(実運用環境では秘密鍵の保護についてちゃんと考えましょう。)
- 変数名
- └─GOOGLE_APPLICATION_CREDENTIALS
- 変数値名
- └─[認証情報ファイルのフルパス]
プログラム作成
1. プロジェクト作成
最新のフレームワークである4.7.2を指定してWindowsデスクトップのコンソールアプリプロジェクトを作成します。
2. アセンブリ参照設定
SpeechSynthesizerを利用するためSystem.Speechへの参照を追加します。
3. パッケージ追加
NuGetパッケージ マネージャー > パッケージ マネージャー コンソールからパッケージをインストールします。
Install-Package Google.Cloud.Speech.V1 -Pre
Install-Package NAudio -Version 1.8.5
Install-Package Newtonsoft.Json -Version 12.0.1
4. コーディング
コードを記述します。
感情分析API他のレスポンス(JSON)クラス
// 感情分析
public class EmotionalElem
{
public string form { get; set; }
public string emotion { get; set; }
}
public class SentimentDetail
{
public string sentiment { get; set; }
public string score { get; set; }
public List<EmotionalElem> emotional_phrase { get; set; }
}
public class SentimentResponse
{
public SentimentDetail result { get; set; }
public int status { get; set; }
public string message { get; set; }
}
// 言い淀み除去 β版
public class Filler
{
public int begin_pos { get; set; }
public int end_pos { get; set; }
public string form { get; set; }
}
public class RemoveFillers
{
public List<Filler> fillers { get; set; }
public string normalized_sentence { get; set; }
public string fixed_sentence { get; set; }
}
public class RemoveFillerResponse
{
public List<RemoveFillers> result { get; set; }
public int status { get; set; }
public string message { get; set; }
}
// COTOHA API レスポンス集約
public class AggregateCotohaResponse
{
public RemoveFillerResponse removeFiller { get; set; }
public SentimentResponse sentiment { get; set; }
}
コード説明
- COTOHA APIのレスポンスJSONテキストからのDeserialize先となるクラス群です。
COTOHAHelperクラス
class COTOHAHelper
{
static Dictionary<int, string> COTOHAErrors = new Dictionary<int, string>{
{99993, "バージョン不正"},
{99995, "予め設定した利用量制限に到達した(for Enterpriseユーザのみ)"},
{99996, "利用量制限に到達した(for Developersユーザのみ)"},
{99997, "短時間に大量のリクエストを行ったため一時的にリクエストを遮断した"},
{99998, "認証エラー"},
{6103, "Parse API でJSON形式不正"}
};
public static string ToString(int status, string message)
{
return COTOHAErrors.ContainsKey(status) ? COTOHAErrors[status] : message;
}
public static string FillerRemovedMsg(RemoveFillerResponse src)
{
return string.Join("", src.result.Select((RemoveFillers rf) => { return rf.fixed_sentence; }).ToArray());
}
public static void HandleDeserializationError(object sender, ErrorEventArgs errorArgs)
{
errorArgs.ErrorContext.Handled = true;
}
static public async Task<R> ProcRequest<R>(HttpClient httpClient, string uri, JObject param, CancellationToken token)
{
StringContent httpContent =
new StringContent(param.ToString(), Encoding.UTF8, "application/json");
HttpResponseMessage responseMessage = await httpClient.PostAsync(uri, httpContent, token);
var body = await responseMessage.Content.ReadAsStringAsync();
var settings = new JsonSerializerSettings
{
Error = HandleDeserializationError
};
return JsonConvert.DeserializeObject<R>(body, settings);
}
static public async Task<AggregateCotohaResponse> Analyze(HttpClient client, string message, CancellationToken token)
{
AggregateCotohaResponse ret = new AggregateCotohaResponse();
var rfParam = new JObject(new JProperty("text", message), new JProperty("do_segment", true));
Task<RemoveFillerResponse> rfTask = ProcRequest<RemoveFillerResponse>(client, "https://api.ce-cotoha.com/api/dev/nlp/beta/remove_filler", rfParam, token);
var smParam = new JObject(new JProperty("sentence", message));
Task<SentimentResponse> smTask = ProcRequest<SentimentResponse>(client, "https://api.ce-cotoha.com/api/dev/nlp/v1/sentiment", smParam, token);
ret.removeFiller = await rfTask;
ret.sentiment = await smTask;
return ret;
}
}
COTOHAHelperクラス説明
- COTOHA API呼び出し、レスポンス/エラー処理のヘルパクラスです。
- 感情分析/言い淀み除去APIのレスポンスを集約します。
メインクラス
コードの見通しをよくするため、音声認識してから音声を出力するまでの処理をTaskとキューで分割しました。関連は以下の図のとおりです。

class Program
{
static bool writeMore = true;
static SemaphoreSlim semaphore = new SemaphoreSlim(1, 1);
static ManualResetEvent evtToWait = new ManualResetEvent(false);
static byte[] silenceImage = new byte[3200];
static CancellationTokenSource tokenSource = new CancellationTokenSource();
static WaveInEvent waveIn = new WaveInEvent();
static SpeechClient.StreamingRecognizeStream streamingCall = SpeechClient.Create().StreamingRecognize();
static SpeechSynthesizer synth = new SpeechSynthesizer();
static Program()
{
Array.Clear(silenceImage, 0, silenceImage.Length);
waveIn.DeviceNumber = 0;
waveIn.WaveFormat = new WaveFormat(16000, 1);
waveIn.DataAvailable += new EventHandler<WaveInEventArgs>(DataAvailable);
}
コード説明
-
主なstaticメンバ(クラス)
- WaveInEvent:マイクから音声を入力するためのNAudioクラス
- SpeechClient.StreamingRecognizeStream:GCP STT Clientクラス
- SpeechSynthesizer:Windows音声合成エンジンアクセスクラス
-
staticコンストラクタではWaveInEvent関連の初期設定をしています。
static byte[] silenceImage = new byte[3200]; ... Array.Clear(silenceImage, 0, silenceImage.Length);固定長3200バイトの無音データを作成しています。本来はDataAvailableイベントで受け取るバッファサイズで毎回処理すべきと思いますが、実測したら変化がなかったので固定長にしました。環境によって違ってくるのかも。
waveIn.WaveFormat = new WaveFormat(16000, 1);音声入力はサンプリングレート:16000、チャンネル数:1(モノラル)です。
static async Task<object> PrepareRecognize()
{
await streamingCall.WriteAsync(
new StreamingRecognizeRequest()
{
StreamingConfig = new StreamingRecognitionConfig()
{
Config = new RecognitionConfig()
{
Encoding = RecognitionConfig.Types.AudioEncoding.Linear16,
SampleRateHertz = 16000,
LanguageCode = "ja-JP",
},
SingleUtterance = false,
InterimResults = false,
}
});
return Task.FromResult(true);
}
PrepareRecognize説明
-
GCP STT Clientの音声認識の動作を指定します。
-
SingleUtterance:false
デフォルトfalseなので指定しなくても良いのですが明示しました。意味は「クライアントが入力ストリームを閉じるまで(gRPC API)、または最大制限時間に達するまでrecognizerは継続的に認識します。(ユーザが話しを止めても音声を待ち続け処理します)。」だそうです。trueなら「単一の発話を検出」になります。
-
InterimResults:false
こちらもデフォルトfalseです。意味は「is_final=trueの結果のみ返します。」です。trueなら「中間結果(仮説)は入手可能になった時点で返却されることがあります。 」で、SingleUtterance:falseと組み合わせると、日本語として認識途中のもの(is_final=false)がダラダラと送られてくる事になります。途中経過なのでほぼ意味不明な文となり、使い道も良く分からなかったので、falseとします。
static async void DataAvailable(object sender, WaveInEventArgs args)
{
try
{
semaphore.Wait();
Google.Protobuf.ByteString content = null;
if (writeMore)
{
content = Google.Protobuf.ByteString.CopyFrom(args.Buffer, 0, args.BytesRecorded);
}
else
{
content = Google.Protobuf.ByteString.CopyFrom(silenceImage, 0, silenceImage.Length);
}
var RecognizeReq = new StreamingRecognizeRequest()
{
AudioContent = content,
};
await streamingCall.WriteAsync(RecognizeReq);
}
catch (TaskCanceledException) { }
catch (Exception){ evtToWait.Set(); }
finally
{
semaphore.Release();
}
}
DataAvailable説明
-
NAudioのWaveInEventで音声入力データが到着すると発生するイベントのハンドラです。音声入力データはGCP STT Clientへ非同期送信します。
-
writeMoreは音声データの処理フラグです。SpeechSynthesizerの音声出力期間中はfalseとなり、GCP STT Clientに無音データを送信します。この変数はsemaphore(SemaphoreSlimクラス)により同時アクセスをケアしています。
try semaphore.Wait(); if (writeMore) finally semaphore.Release(); -
例外の発生をメイン処理へevtToWait(ManualResetEventクラス)で通知します。メイン処理はこれを契機として全体の処理を終了させます。
catch (Exception){ evtToWait.Set(); }
static async Task<object> ProcRecognitionResult(BlockingCollection<StreamingRecognitionResult> dst, CancellationToken token)
{
try
{
while (await streamingCall.ResponseStream.MoveNext(token))
{
foreach (StreamingRecognitionResult result in streamingCall.ResponseStream.Current.Results)
{
dst.TryAdd(result.Clone(), Timeout.Infinite, token);
}
}
}
catch (Grpc.Core.RpcException)
{
if (token.IsCancellationRequested)
{
token.ThrowIfCancellationRequested();
}
}
return Task.FromResult(true);
}
ProcRecognitionResult説明
- 音声認識結果をGCP STTから受け取りRecognitionResultQueueキューへセットします。
static async Task<object> AnalyzeText(BlockingCollection<StreamingRecognitionResult> src, BlockingCollection<string> dst, HttpClient client, CancellationToken token)
{
while (!src.IsCompleted)
{
try
{
StreamingRecognitionResult data;
bool success = src.TryTake(out data, System.Threading.Timeout.Infinite, token);
if (success)
{
string transcript = string.Join("", data.Alternatives.Select((SpeechRecognitionAlternative al) => { return al.Transcript; }).ToArray());
if (!string.IsNullOrEmpty(transcript))
{
Console.WriteLine("\n" + transcript);
bool needPrompt = true;
Console.WriteLine("\n> COTOHA APIの処理結果");
AggregateCotohaResponse resp = await COTOHAHelper.Analyze(client, transcript, token);
if (resp.sentiment.status == 0)
{
Console.WriteLine("> 感情: " + resp.sentiment.result.sentiment);
resp.sentiment.result.emotional_phrase.ForEach((EmotionalElem emt) => {
Console.WriteLine("> +--- {0} : {1}", emt.form, emt.emotion ); });
}
else
{
var msg = COTOHAHelper.ToString(resp.sentiment.status, resp.sentiment.message);
Console.WriteLine("> 感情分析エラー: status [{0}] message [{1}]", resp.sentiment.status, msg);
}
if (resp.removeFiller.status == 0)
{
var after = COTOHAHelper.FillerRemovedMsg(resp.removeFiller);
Console.WriteLine("> 言い淀み除去: " + after);
if (!string.IsNullOrEmpty(after))
{
dst.TryAdd(after, System.Threading.Timeout.Infinite, token);
needPrompt = false;
}
}
else
{
var msg = COTOHAHelper.ToString(resp.removeFiller.status, resp.removeFiller.message);
Console.WriteLine("> 言い淀み除去エラー: status [{0}] message [{1}]", resp.removeFiller.status, msg);
}
if (needPrompt)
{
Console.WriteLine("\nお話しください。(改行で終了)");
}
}
}
}
catch (Exception e)
{
return Task.FromException<object>(e);
}
}
return Task.FromResult(true);
}
AnalyzeText説明
- 音声認識の結果テキストをRecognitionResultQueueキューから取り出し、COTOHA API(感情分析、言い淀み除去)へ送信、レスポンスをコンソールへ表示します。言い淀み除去結果テキストはAudioOutputQueueキューへセットします。(コンソール表示を別Taskにしても良かったかも。)
static Task<string> Speak(BlockingCollection<string> src, CancellationToken token)
{
while (!src.IsCompleted)
{
try
{
string data;
bool success = src.TryTake(out data, System.Threading.Timeout.Infinite, token);
if (success && !string.IsNullOrEmpty(data))
{
try
{
semaphore.Wait();
writeMore = false;
synth.SpeakAsync(data);
}
catch (Exception e)
{
return Task.FromException<string>(e);
}
finally
{
semaphore.Release();
}
}
}
catch (Exception e)
{
return Task.FromException<string>(e);
}
}
return Task.FromResult("done.");
}
Speak説明
- 言い淀み除去結果テキストをAudioOutputQueueキューから取り出し、音声を合成(SpeechSynthesizerへ非同期リクエスト)します。
static void synthesizer_SpeakCompleted(object sender, SpeakCompletedEventArgs e)
{
try
{
semaphore.Wait();
writeMore = true;
Console.WriteLine("\nお話しください。(改行で終了)");
}
finally
{
semaphore.Release();
}
}
synthesizer_SpeakCompleted説明
- SpeechSynthesizerでテキスト読み上げ完了時に発生するイベントのハンドラです。マイクからの音声データにより音声認識を再開させるため、writeMore=trueに戻します。
static void Main(string[] args)
{
try
{
using (HttpClientHandler httpClientHandler = new HttpClientHandler()
{
ClientCertificateOptions = ClientCertificateOption.Automatic,
PreAuthenticate = true,
UseProxy = true,
Proxy = new WebProxy("[protocol://host:port]", true)
})
using (HttpClient client = new HttpClient(new AccessTokenHandler(httpClientHandler)))
using (BlockingCollection<StreamingRecognitionResult> RecognitionResultQueue = new BlockingCollection<StreamingRecognitionResult>(3))
using (BlockingCollection<string> AudioOutputQueue = new BlockingCollection<string>(3))
{
try
{
synth.SpeakCompleted +=
new EventHandler<SpeakCompletedEventArgs>(synthesizer_SpeakCompleted);
synth.SetOutputToDefaultAudioDevice();
var token = tokenSource.Token;
PrepareRecognize().GetAwaiter().GetResult();
Console.WriteLine("お話しください。(改行で終了)");
waveIn.StartRecording();
var tasks = new List<Task>();
tasks.Add(Task.Run(() => ProcRecognitionResult(RecognitionResultQueue, token)));
tasks.Add(Task.Run(() => AnalyzeText(RecognitionResultQueue, AudioOutputQueue, client, token)));
tasks.Add(Task.Run(() => Speak(AudioOutputQueue, token)));
while (!evtToWait.WaitOne(1000))
{
if (Console.KeyAvailable)
{
var dummy = Console.ReadKey();
break;
}
}
Console.WriteLine("\n終了しています...。");
waveIn.StopRecording();
tokenSource.Cancel();
Task.WaitAll(tasks.ToArray());
}
catch (AggregateException ae)
{
ae.Handle((e) => {return true;});
}
}
}
finally
{
evtToWait.Dispose();
synth.Dispose();
waveIn.Dispose();
}
}
}
Main説明
- 全体のメイン処理です。必要なオブジェクトを生成し、初期設定、音声入力を開始後、各Taskをバックグラウンド実行します。キー入力またはManualResetEventの(例外)通知を待ち受け、いずれかが発生すれば処理終了です。(待ち受け処理が地味に面倒...。※参考3)バックグラウンドTaskの処理はCancellationTokenによりキャンセルさせます。
-
以下の2行はCOTOHA APIへの接続に使用するProxy設定です。Proxyを使用しない場合、コメントアウトすれば動作すると思います(未検証)。
UseProxy = true, Proxy = new WebProxy("[protocol://host:port]", true)
AccessTokenクラス/アクセストークン取得APIのレスポンス(JSON)クラス
前回記事から変更がないためそちらを参照してください。
AccessTokenHandlerクラス
class AccessTokenHandler : DelegatingHandler
{
private HttpClient httpClient = new HttpClient();
private AccessToken accesstoken = new AccessToken();
static SemaphoreSlim semaphore = new SemaphoreSlim(1, 1);
public AccessTokenHandler(HttpMessageHandler innerContent)
: base(innerContent)
{
httpClient = new HttpClient(innerContent);
}
protected override async Task SendAsync(HttpRequestMessage request, CancellationToken cancellationToken)
{
try
{
semaphore.Wait();
if (!accesstoken.IsValidToken())
{
JObject tokenRequest = new JObject(
new JProperty("grantType", "client_credentials"),
new JProperty("clientId", "[Developer Client id]"),
new JProperty("clientSecret", "[Developer Client secret]")
);
StringContent httpContent = new StringContent(tokenRequest.ToString(), Encoding.UTF8, "application/json");
HttpResponseMessage responseMessage = await httpClient.PostAsync("https://api.ce-cotoha.com/v1/oauth/accesstokens", httpContent);
string body = await responseMessage.Content.ReadAsStringAsync();
TokenResponse resp = JsonConvert.DeserializeObject(body);
accesstoken.SetToken(resp);
}
}
finally {
semaphore.Release();
}
request.Headers.Authorization = new AuthenticationHeaderValue("Bearer", accesstoken.token);
return await base.SendAsync(request, cancellationToken);
}
}
AccessTokenHandlerクラス説明
-
基本構成は前回記事と同様ですが、以下について変更しました。
アクセストークン取得を1Taskに限定するための同期プリミティブをNito.AsyncExからSemaphoreSlimに変更しました。(今のところ問題なさげです。)
検証
ビルドして出来上がった.exeをコマンドラインから起動し、感情分析のリクエストサンプルを読み上げてみました。
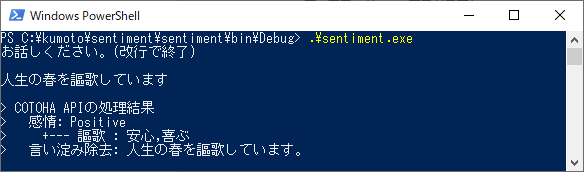
実行結果です。サンプルどおり"ポジティブ"の感情です。"謳歌"のフレーズもサンプルどおり"喜ぶ,安心"の感情に分類しているようです。
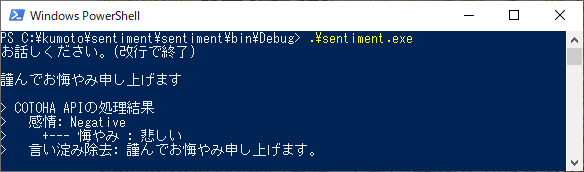
"ネガティブ"もちゃんと判定してくれてます。
上の例は手紙に出てきそうな文でしたが、少しくだけた「話し言葉」ではどうでしょうか。
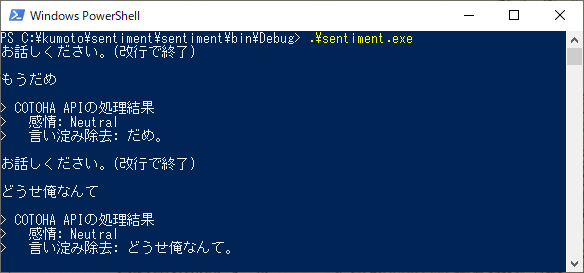
"ネガティブ"かと思ったら"ニュートラル"でした。〇〇相談とかではありそうな言葉ですが...。
【蛇足】言い淀み除去のサンプルです。
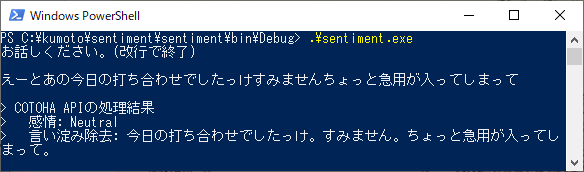
言い淀み除去OKです!
【蛇足2】言い淀みだけで中身がないと。
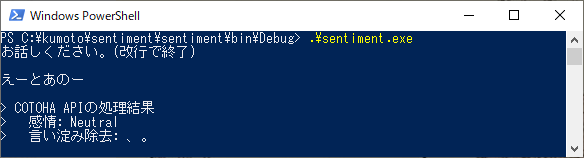
...orz
課題
- 言い淀み除去した結果が句読点等だけ(例:"、。")でもそのままTTSに送っている。発音できないデータだけの場合はフィルタする。
まとめ
数例だけではありますが、基本は"書き手の"「書き言葉」を感情分析するAPIのようです。議事録テープ起こしとかで感情分析に利用するのかなぁと漠然とユースケースを考えていたのですが、それは難しそうです。
コールセンターのような対話でも「話し言葉」が基本になるでしょうし、その場合は口調・語気等での感情分析も必要だと思われるので、テキストのみを対象とした感情分析って...やっぱりユースケースが思いつきませんでした。(※あくまで個人の感想です)
前回記事での課題(言い淀みがそもそも音声入力できない、繰返し対話できない)も両方クリアできたっぽいので、今回は良しとします。
