C# コンソールアプリケーション 自然言語解析 音声合成 音声認識
COTOHAで音声から言い淀みを取り除いてみた
はじめに
実際に使えそうなアプリネタ第3弾と思っていましたが、ちょっと寄り道です。
岩手岩泉町在住のプログラマAです。
今回はNTTコミュニケーションズのCommunication Engine"COTOHA API"の試用レポートです。

COTOHA APIはサービスメニューを見ると分かるとおり、音声認識(Speech to Text/STT)そのものではなく、認識後のテキストを処理するための自然言語解析のAPIです。
機能別に10のAPIが用意されていて、必要なものを呼出して使う設計となっているようです。それらのうち(β版ですが)、実務で役に立ちそうな2つのAPIを使ってみました。
- 言い淀み除去 β版
- 音声認識結果誤り検知 β版
検証プログラムの構成は、WindowsのSTT API(SpeechRecognitionEngine)で音声をテキストに変換し、COTOHA APIで言い淀みを除去した結果テキストをWindowsのText to Speech/TTS API(SpeechSynthesizer)でテキストから音声に変換し、スピーカに出力する方式としました。
うまくいけば、言い淀みだらけの会話文から意味のある文章だけをPCがオウム返ししてくれるはずですが、結果やいかに...。
プログラム
C#、Windowsデスクトップ/コンソールアプリケーション、Recognition API(STT)、Synthesis API(TTS)
実行/開発環境
- Windows 10 Pro バージョン 1809(デスクトップPC )
- Visual Studio 2017 Community
- ヘッドセット
- スピーカ(ヘッドセット)
NuGetパッケージ
- Nito.AsyncEx 4.0.1
- Newtonsoft.Json 12.0.1
準備
1.マイク、スピーカ準備
PCの録音デバイスとしてヘッドセットを、再生デバイスとしてスピーカ/ヘッドセットを接続し、よしなに動作を確認しておきます。
Windowsの設定 > プライバシー > 音声認識でオンライン音声認識は「オフ」とします。(=クラウドベースの音声認識ではない、はず)
2.COTOHA APIアカウント作成
COTOHA API Portalからアカウントを登録します。for Developersなら無料です。(以下の制限あり)
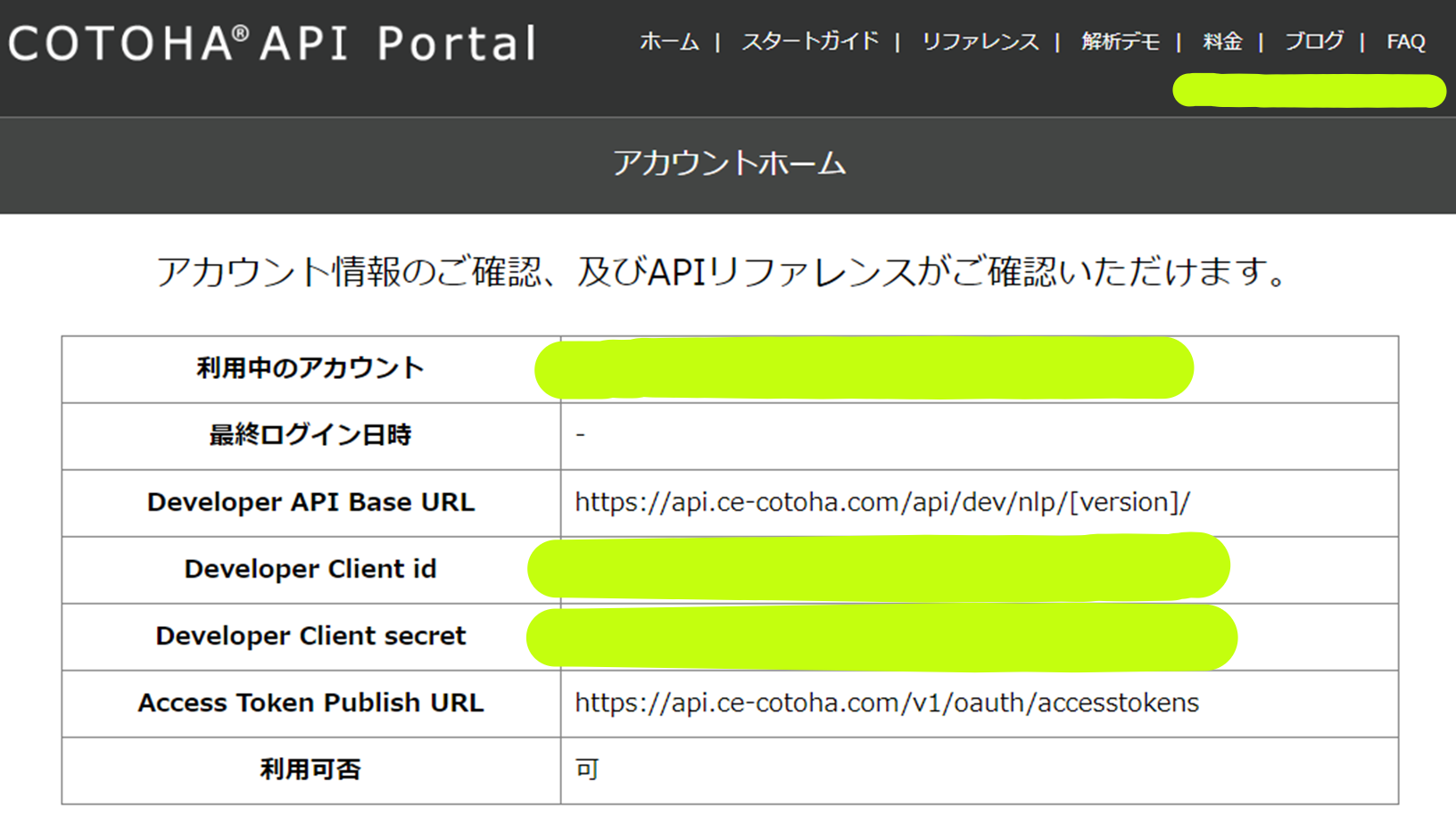
アカウント登録後、アカウントホームで登録情報を確認できます。"Developer Client id"、"Developer Client secret"はアクセストークンの取得時に必要となります。(後述)
プログラム作成
1. プロジェクト作成
最新のフレームワークである4.7.2を指定してWindowsデスクトップのコンソールアプリプロジェクトを作成します。

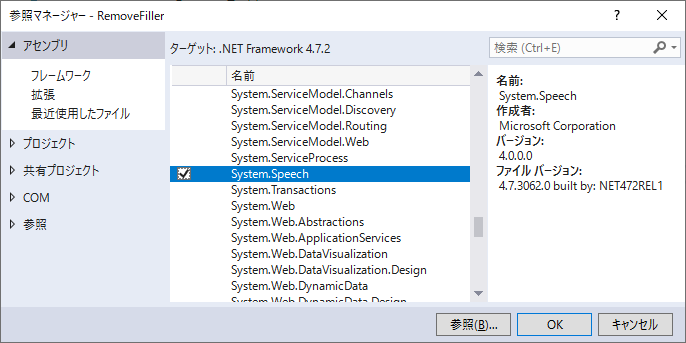
2. アセンブリ参照設定
SpeechRecognitionEngine/SpeechSynthesizerを利用するためSystem.Speechへの参照を追加します。
3. パッケージ追加
NuGetパッケージ マネージャー > パッケージ マネージャー コンソールからパッケージをインストールします。
Install-Package Nito.AsyncEx -Version 4.0.1
Install-Package Newtonsoft.Json -Version 12.0.1
4. コーディング
コードを記述します。
言い淀み除去API他のレスポンス(JSON)クラス
// 言い淀み除去 β版
public class Filler
{
public int begin_pos { get; set; }
public int end_pos { get; set; }
public string form { get; set; }
}
public class RemoveFillers
{
public List fillers { get; set; }
public string normalized_sentence { get; set; }
public string fixed_sentence { get; set; }
}
public class RemoveFillerResponse
{
public List result { get; set; }
public int status { get; set; }
public string message { get; set; }
}
// 音声認識結果誤り検知 β版
public class Candidate
{
public int begin_pos { get; set; }
public int end_pos { get; set; }
public string form { get; set; }
public string score { get; set; }
}
public class MisrecognitionDetail
{
public List candidates { get; set; }
public string score { get; set; }
}
public class DetectMisrecognitionResponse
{
public string message { get; set; }
public MisrecognitionDetail result { get; set; }
public int status { get; set; }
}
メインクラス
class Program
{
static SpeechRecognitionEngine recognizer = null;
static SpeechSynthesizer synth = null;
static HttpClient client = null;
static bool speakCompleted = false;
static Dictionary COTOHAErrors = new Dictionary{
{99993, "バージョン不正"},
{99995, "予め設定した利用量制限に到達した(for Enterpriseユーザのみ)"},
{99996, "利用量制限に到達した(for Developersユーザのみ)"},
{99997, "短時間に大量のリクエストを行ったため一時的にリクエストを遮断した"},
{99998, "認証エラー"},
{6103, "Parse API でJSON形式不正"}
};
static void Main(string[] args)
{
var httpClientHandler = new HttpClientHandler();
httpClientHandler.ClientCertificateOptions = ClientCertificateOption.Automatic;
httpClientHandler.PreAuthenticate = true;
httpClientHandler.UseProxy = true;
httpClientHandler.Proxy = new WebProxy("[protocol://host:port]", true);
client = new HttpClient(new AccessTokenHandler(httpClientHandler));
synth = new SpeechSynthesizer();
synth.SpeakCompleted +=
new EventHandler(synthesizer_SpeakCompleted);
synth.SetOutputToDefaultAudioDevice();
recognizer =
new SpeechRecognitionEngine(
new System.Globalization.CultureInfo("ja-JP"));
recognizer.LoadGrammar(new DictationGrammar());
recognizer.SpeechRecognized +=
new EventHandler(recognizer_SpeechRecognized);
recognizer.SetInputToDefaultAudioDevice();
recognizer.RecognizeAsync(RecognizeMode.Multiple);
Console.WriteLine("どうぞ話してください。");
while (!speakCompleted)
{
Thread.Sleep(100);
}
recognizer.Dispose();
synth.Dispose();
}
static public async Task ProcRequest(HttpClient httpClient, string uri, JObject param)
{
StringContent httpContent =
new StringContent(param.ToString(), Encoding.UTF8, "application/json");
HttpResponseMessage responseMessage = await httpClient.PostAsync(uri, httpContent);
var body = await responseMessage.Content.ReadAsStringAsync();
var settings = new JsonSerializerSettings
{
Error = HandleDeserializationError
};
return JsonConvert.DeserializeObject(body, settings);
}
static async void recognizer_SpeechRecognized(object sender, SpeechRecognizedEventArgs e)
{
try
{
recognizer.RecognizeAsyncCancel();
Console.WriteLine("\n認識テキスト: "+e.Result.Text);
var rfParam = new JObject(new JProperty("text", e.Result.Text), new JProperty("do_segment", true));
var dmParam = new JObject(new JProperty("sentence", e.Result.Text));
Task rfTask =
ProcRequest(client, "https://api.ce-cotoha.com/api/dev/nlp/beta/remove_filler", rfParam);
Task dmTask =
ProcRequest(client, "https://api.ce-cotoha.com/api/dev/nlp/beta/detect_misrecognition", dmParam);
RemoveFillerResponse rfResp = await rfTask;
DetectMisrecognitionResponse dmResp = await dmTask;
if (rfResp.status != 0)
{
var msg = COTOHAErrors.ContainsKey(rfResp.status) ? COTOHAErrors[rfResp.status] : rfResp.message;
throw new Exception(string.Format("言い淀み除去エラー: status [{0}] message [{1}]", rfResp.status, msg));
}
if (dmResp.status != 0)
{
var msg = COTOHAErrors.ContainsKey(dmResp.status) ? COTOHAErrors[dmResp.status] : dmResp.message;
throw new Exception(string.Format("音声認識結果誤り検知エラー: status [{0}] message [{1}]", dmResp.status, msg));
}
if (float.Parse(dmResp.result.score) > 0.9)
{
StringBuilder buf = new StringBuilder();
buf.AppendFormat("音声認識誤りです。\n\nスコア\t誤り\n-----------------------------\n");
if (dmResp.result != null)
{
dmResp.result.candidates.ForEach((Candidate cd) => { buf.AppendFormat("{0}\t{1}\n", cd.score.Substring(0, 6), cd.form); });
}
throw new Exception(buf.ToString());
}
var after = string.Join("", rfResp.result.Select((RemoveFillers rf) => { return rf.fixed_sentence; }).ToArray());
Console.WriteLine("\n言い淀み除去後: " + after);
if (!string.IsNullOrEmpty(after))
{
synth.SpeakAsync(after);
}
}
catch (Exception ex)
{
Console.WriteLine();
Console.WriteLine(ex.Message);
speakCompleted = true;
}
}
static void synthesizer_SpeakCompleted(object sender, SpeakCompletedEventArgs e)
{
speakCompleted = true;
}
public static void HandleDeserializationError(object sender, ErrorEventArgs errorArgs)
{
errorArgs.ErrorContext.Handled = true;
}
}
コード説明
-
以下の2行はProxyの設定です。Proxyを使用しない場合、コメントアウトすれば動作すると思います(未検証)。
httpClientHandler.UseProxy = true; httpClientHandler.Proxy = new WebProxy("[protocol://host:port]", true); -
言い淀み除去API等でエラーが発生した場合、resultフィールドが空となり、JsonConvert.DeserializeObject()が例外を出力するため、HandleDeserializationErrorハンドラでエラーを無視しています。
- エラーレスポンス
-
{"result":{},"message":"An error has occurred.","status":9901}
- 例外
-
Newtonsoft.Json.JsonSerializationException: Cannot deserialize the current JSON object (e.g. {"name":"value"}) into type 'System.Collections.Generic.List`1[ConsoleApp1.RemoveFillers]' because the type requires a JSON array (e.g. [1,2,3]) to deserialize correctly.
元ネタは参考5の記事です。
-
音声認識結果誤り検知APIのレスポンスで、"入力全体の誤り度合い"(スコア)が"0.9"より大きい場合は、誤り検知の詳細のみ出力して音声は出力しません。スコアは
0から1の値を取り、誤り度合いが高いと1に近づく。という値だそうです。※ しきい値の"0.9"には根拠ないです。
AccessTokenクラス/アクセストークン取得APIのレスポンス(JSON)クラス
class AccessToken
{
public string token { get; set; }
public DateTime tokenExpire { get; set; }
public AccessToken()
{
token = "";
tokenExpire = DateTime.MinValue;
}
public bool IsValidToken()
{
return (!token.Equals("") && tokenExpire > DateTime.Now);
}
public void SetToken(TokenResponse obj)
{
if (obj == null)
{
token = "";
tokenExpire = DateTime.MinValue;
}
else
{
token = obj.access_token;
var expireIn = TimeSpan.FromSeconds(Int64.Parse(obj.expires_in));
tokenExpire = DateTime.Now + expireIn;
}
}
}
public class TokenResponse
{
public string access_token { get; set; }
public string token_type { get; set; }
public string expires_in { get; set; }
public string scope { get; set; }
public string issued_at { get; set; }
}
コード説明
-
言い淀み除去API等へアクセスする際、アクセストークンが必要となります。AccessTokenクラスはアクセストークンデータの処理をカプセル化したものです。
-
トークンの有効期限計算は厳密には以下の計算式となるはずですが、
issued_at(トークン発行日時) + expires_in(残り有効期限(秒))今回は手抜きして
現在時刻(PC) + expires_in(残り有効期限(秒))としています。(発行されたトークンは24時間有効でした。)
AccessTokenHandlerクラス
class AccessTokenHandler : DelegatingHandler
{
private HttpClient httpClient = new HttpClient();
private AccessToken accesstoken = new AccessToken();
private readonly AsyncLock _mutex = new AsyncLock();
public AccessTokenHandler(HttpMessageHandler innerContent)
: base(innerContent)
{
httpClient = new HttpClient(innerContent);
}
protected override async Task SendAsync(HttpRequestMessage request, CancellationToken cancellationToken)
{
using (await _mutex.LockAsync())
{
if (!accesstoken.IsValidToken())
{
JObject tokenRequest = new JObject(
new JProperty("grantType", "client_credentials"),
new JProperty("clientId", "[Developer Client id]"),
new JProperty("clientSecret", "[Developer Client secret]")
);
StringContent httpContent = new StringContent(tokenRequest.ToString(), Encoding.UTF8, "application/json");
HttpResponseMessage responseMessage = await httpClient.PostAsync("https://api.ce-cotoha.com/v1/oauth/accesstokens", httpContent);
string body = await responseMessage.Content.ReadAsStringAsync();
TokenResponse resp = JsonConvert.DeserializeObject(body);
accesstoken.SetToken(resp);
}
}
request.Headers.Authorization = new AuthenticationHeaderValue("Bearer", accesstoken.token);
return await base.SendAsync(request, cancellationToken);
}
}
コード説明
-
AccessTokenHandlerクラスは言い淀み除去API等の呼出し時、有効なアクセストークンをヘッダに注入します。アクセストークンが存在しない場合や有効期限切れの場合、HttpClientによりアクセストークンを取得します。DelegatingHandlerによるトークン設定処理の元ネタは参考4の記事です。
-
以下の2行はアクセストークン取得APIへのアクセスに必要となるクライアントID、クライアントシークレットを設定しています。準備2のCOTOHA APIアカウント作成で取得した値を設定します。
new JProperty("clientId", "[Developer Client id]"), new JProperty("clientSecret", "[Developer Client secret]")
検証
ビルドして出来上がった.exeをコマンドラインから起動し、言い淀み除去のリクエストサンプルを読み上げてみました。
実行結果です。"認識テキスト:"の行にSpeechRecognitionEngineによる音声認識の結果を表示します。
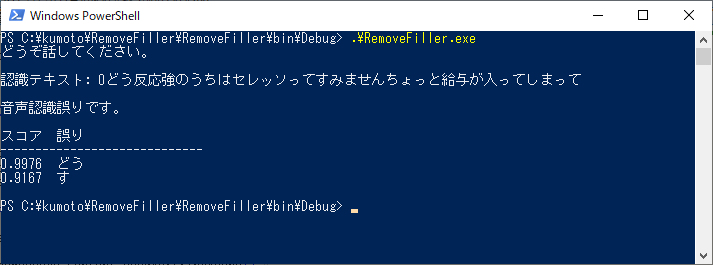
...給与が入ってくれるのは嬉しいんだけどね。
【音声認識誤りの見方】
- 認識テキストのうち、認識誤りが疑われる箇所とそのスコアを表示しています。
- スコアの見方は"入力全体の誤り度合い"と同じで"誤り度合いが高いと1に近づく"となります。
- スコアは小数点以下4桁だけ表示していますが、APIからのレスポンスのままだと桁数が多くて見づらいので切詰めています。
気を取り直して、もいちどチャレンジです。SpeechRecognitionEngineは「てん」「まる」と発声すると「、」「。」にテキスト変換してくれるようです。便利(なのか?)。
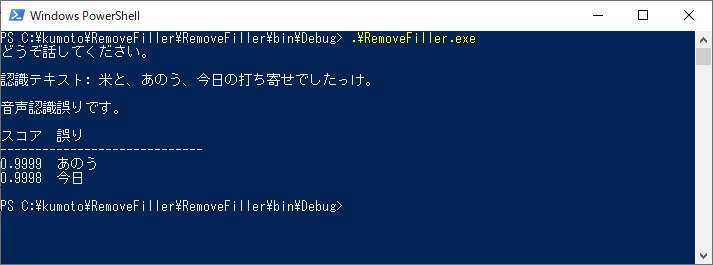
「まる」で文の区切りと認識してSpeechRecognizedイベント発生のようです。"あのう"はテキストに変換してくれたけど、またしても音声認識誤りかぁ...。このままだと一度もスピーカから音でないので、ちょっとズルして。
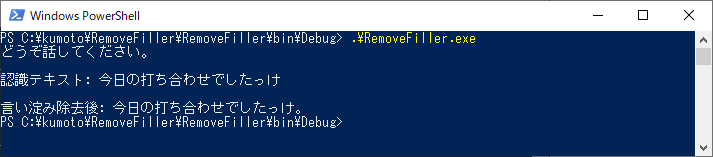
今度は音声認識誤りもなく、ようやくスピーカから音が出てくれました!
ちゃんと「。」も付けてくれてるようです。
課題
- SpeechRecognitionEngineの使い方を調べる。言い淀みをそのままスルーできない?(本末転倒。STTは複数候補から最も近そうな文を選んでテキストを提示してくれているので、難しい気が)
- 対話型で繰返し音声入力/出力したい場合、音声出力の間は音声入力をカットする制御が必要。今回は1回音声入力/出力したらプログラムは終了するのでケアしていない。スピーカから出た音声をマイクが拾うのを防止。
まとめ
ホントは言い淀み除去だけ試してみる予定でしたが、SpeechRecognitionEngineとの組合せでは期待した結果になりませんでした。
検証のとおり、わざと言い淀みをマイクで話しかけてもSpeechRecognitionEngineはムリヤリ近そうな日本語に変換してくれるのです。
それでは、という事で音声認識の誤り検知も併用してみたのですが、結果は...。
SpeechRecognitionEngineの使い方が良くない、別のSTTサービスならそんな事はない、とか色々ツッコミどころ満載な記事になってしまいましたが、ご指摘いただけると幸いです。
